開発環境の構築
MANPの設定
https://www.udemy.com/course/backend-tutorial/learn/lecture/23810492
SQLクライアント
https://www.udemy.com/course/backend-tutorial/learn/lecture/25428042
プラグインの設定
PHP
https://www.udemy.com/course/backend-tutorial/learn/lecture/23978916
Apache
https://www.udemy.com/course/backend-tutorial/learn/lecture/25645590
PHPのデバックを有効にする
https://www.udemy.com/course/backend-tutorial/learn/lecture/23910330
基礎知識
グローバルIPとプライベートIP
グロバールIPとプライベートIPは決められた範囲がある
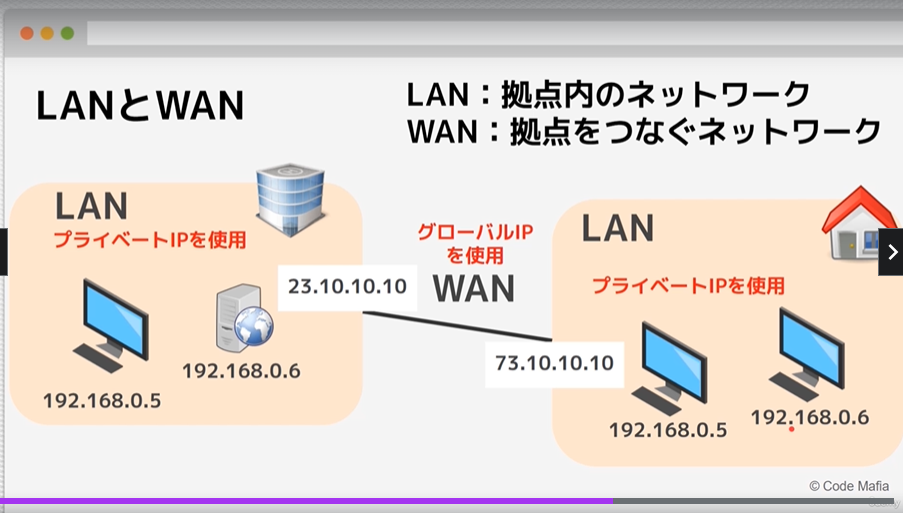
LANとWAN
LAN は拠点内のネットワーク
WAN は拠点をつなぐネットワーク
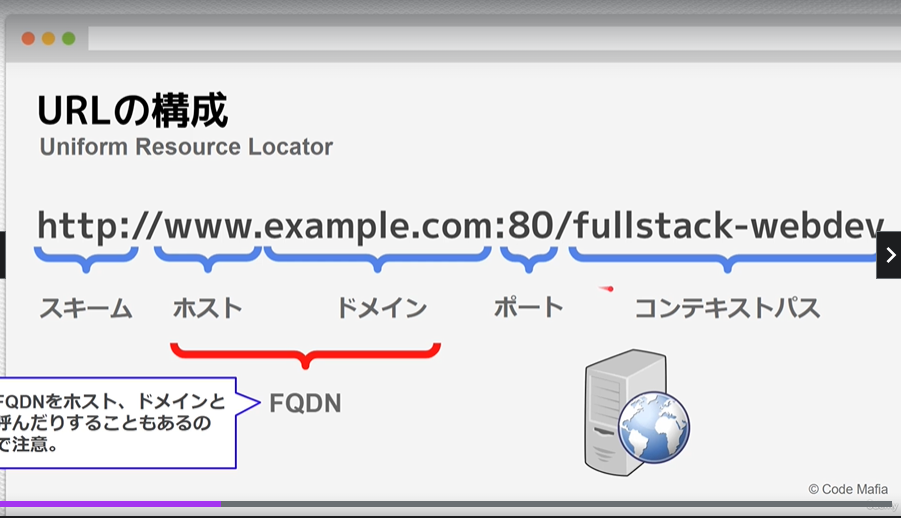
URLの構成
httpはポート80が自動で割り振られる
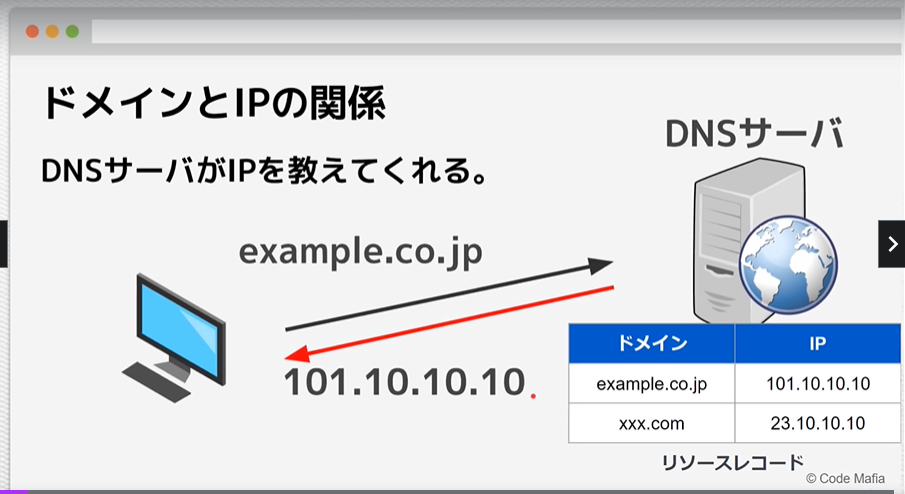
ドメインとIPアドレス
DNSサーバーが、ドメインのIPアドレスを教えてくれる
→「名前解決」という
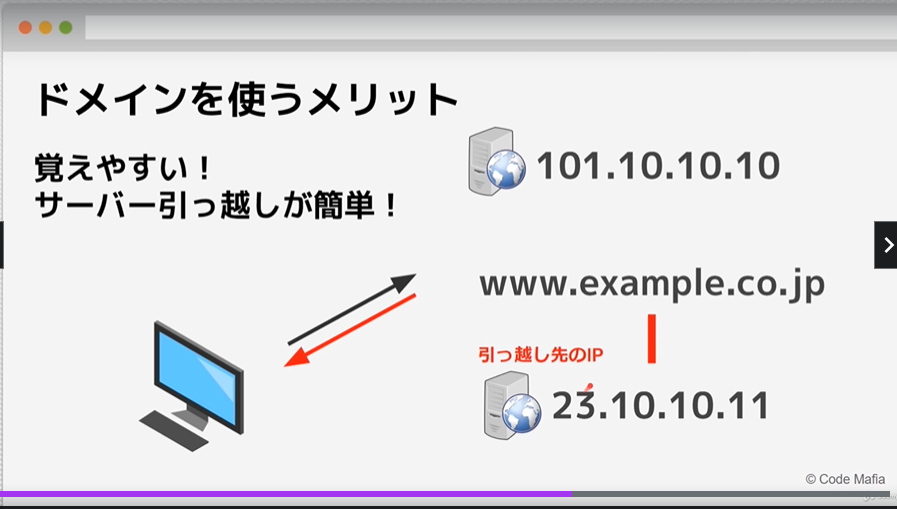
ドメインを使用すると、サーバーを変えた際にIPが変わっても同じドメインで繋げる事ができる。
※ユーザーはIPアドレスの違いを気にする必要はない
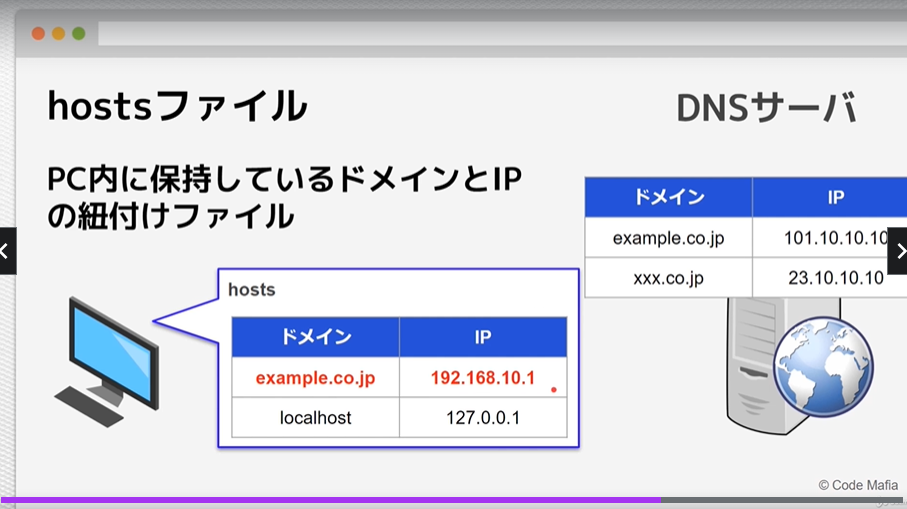
hostsファイル
PC内に保持しているドメインとIPの紐づけファイル。
PC内に存在している組み合わせであれば、DNSサーバーを見に行かない。
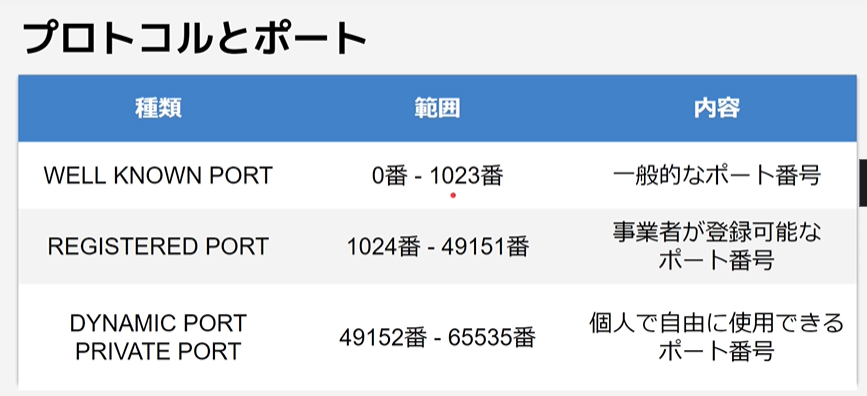
プロトコル
HTTPやFTPなどプロトコルによってデフォルトのポートは決まっている。
ただ、デフォルト値を持っているだけで変更することは可能。
自分でポートを割当てる場合は、「DYNAMIC PORT」「PRIVATE PORT」から割当てるのがベター

TCP/UDPは、他のプロトコルと組み合わせて使用する。
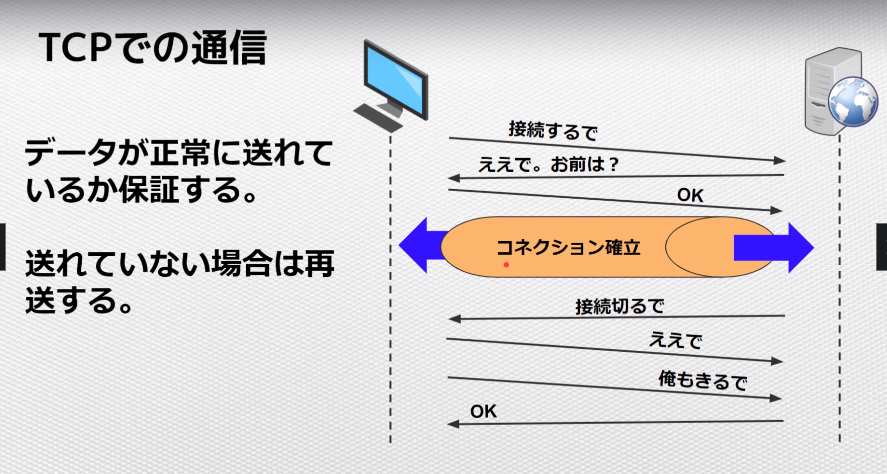
TCP
コネクションを確立してデータを送信する。
データが正常に送れているか保証する。
送れていない場合は、再送する。
UDP
データが正常に送れているかは保証しない。
データを投げつけるだけ。
データが欠落していた場合、その部分を無視する。
その分、TCPよりも高速(パフォーマンスが良い)
データ欠落していても問題無く、パフォーマンスを優先する時に使用する。
※IP電話やゲーム

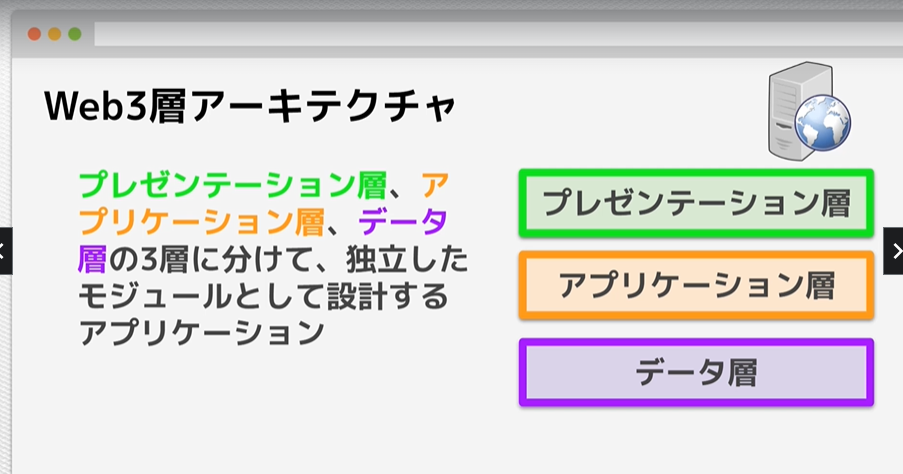
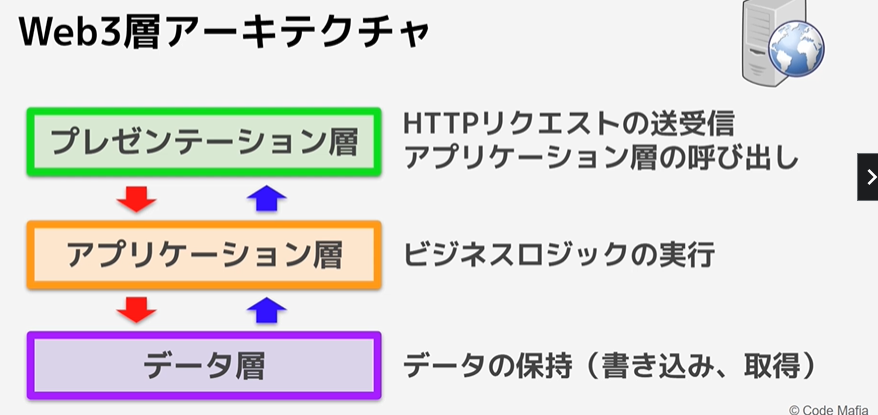
Web3層アーキテクチャ
・プレゼンテーション層
・アプリケーション層
・データ層
この層が混在しているとメンテナンスがしにくい
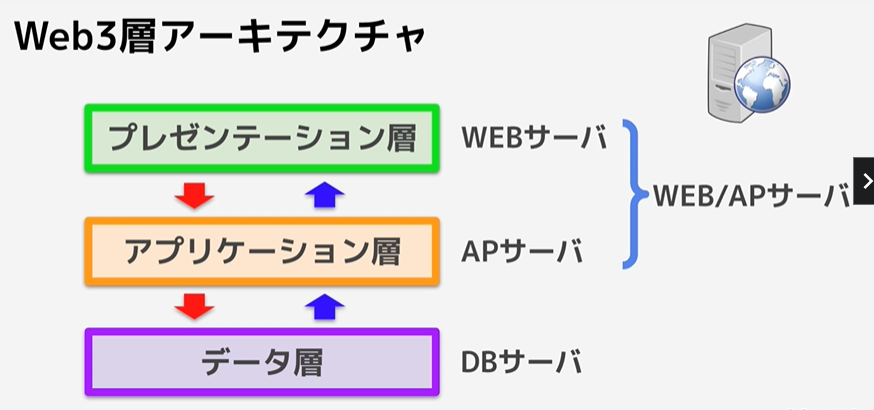
一口にサーバーと言っても、実は分かれている
・WEBサーバー
・AP(アプリケーション)サーバー
・DBサーバー
PHPとWEB
httpでの通信について
httpを使用した代表的なメソッドには、
・GET → データの取得
・POST → データの作成、更新
がある。

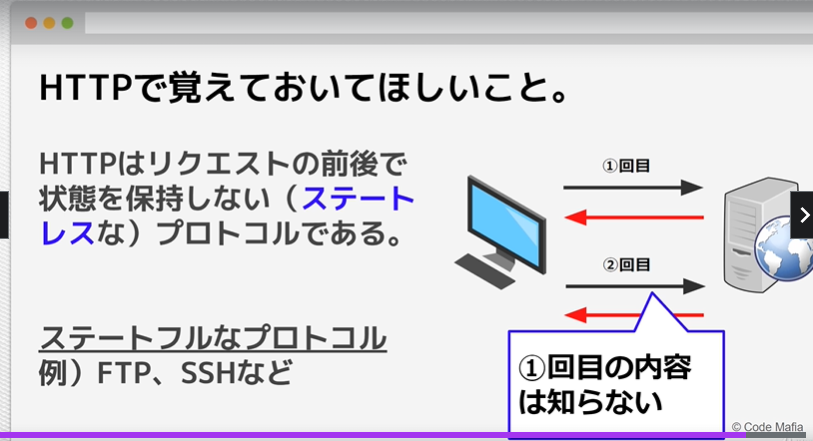
ステートレスな通信
HTTPはリクエストの前後で状態を保持しない(ステートレス)プロトコル
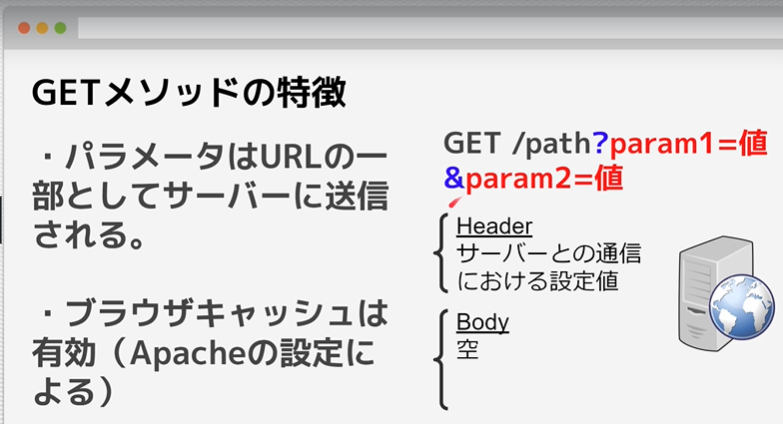
GETメソッドについて
・パラメータはURLの一部としてサーバーに送信される。
・ブラウザキャッシュは有効(Apacheの設定による)
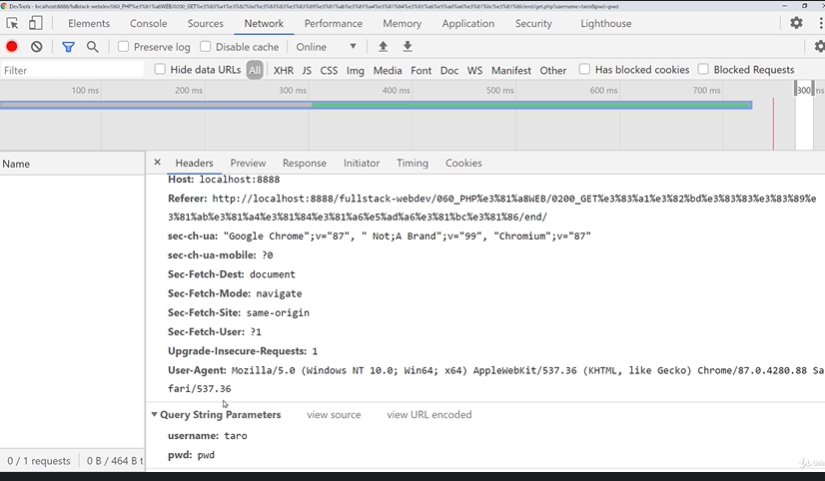
→ディベロッパーツールの「Network」からGETの値を確認する事ができる。
Herdersの「Query String Parmeters」の値がGETで送られた値となる。
// フォーム
<form action="get.php" method="GET"> ← medhodの指定。省略した場合、GETの指定になる。
<input type="text" name="username">
<input type="password" name="pwd">
<input type="submit" value="ボタンを押してね">
</form>// get.php
<div>
名前:<?php echo $_GET['username']; ?> ← GETで送った値は、スーパーグローバル変数に連想配列で格納されてる
</div>
<div>
パスワード:<?php echo $_GET['pwd']; ?>
</div>・GETの取得方法
$_GET[‘取得したい値のキー’]
POSTメソッドについて
・パラメータはメッセージBodyに設定される
・ブラウザキャッシュは無効

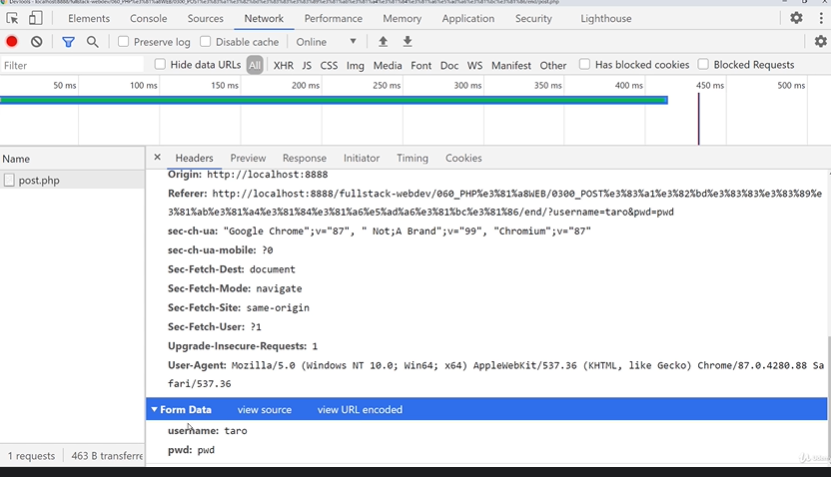
→ディベロッパーツールの「Network」からPOSTの値を確認する事ができる。
Herdersの「Form Data」の値がBodyが持っているpostの値。
// フォーム
<form action="post.php" method="POST"> ← medhodの指定。省略した場合、GETの指定になる。
<input type="text" name="username">
<input type="password" name="pwd">
<input type="submit" value="ボタンを押してね">
</form>// post.php
<div>
名前:<?php echo $_POST['username']; ?> ← POSTで送った値は、スーパーグローバル変数に連想配列で格納されてる
</div>
<div>
パスワード:<?php echo $_POST['pwd']; ?>
</div>・POSTの取得方法
$_POST[‘取得したい値のキー’]
GETとPOSTの使い分け
・URLは最大2000文字程度までしか設定できない。
→2000文字を超えるような値の場合は、POSTを使うしかない
・GETではパラメータを含めて共有できる。
→GETなら同一URLでもパラメータによってページの内容を変える事が可能だが、
POSTの場合は不可。
GETメソッドは何かデータを表示させる際に優れたメソッド。
// test.php
$students = [
'1' => [
'name' => 'taro',
'age' => 15,
],
'2' => [
'name' => 'hanako',
'age' => 14,
],
];
//GETのidがnullでなければ取得した値、nullなら「1」を入れる(null合体演算子)
$id = $_GET['id'] ?? 1;
$student = $students[$id];
$name = $student['name'];
$age = $student['age'];
?>
<div><?php echo "{$name}は{$age}才です。"; ?></div>①test.php
→表示内容:taroは15才です。
②test.php?id=2
→表示内容:hanakoは14才です。
渡す値について(配列・隠しフィールド)
配列で値を渡す
//通常の配列
<input type="text" name="members[]">
<input type="text" name="members[]">
<input type="text" name="members[]">
$members = $_GET['members']; ←methodが「GET」の場合。「POST」でも可能。
echo $members[0];//連想配列
<input type="text" name="members['id']">
<input type="text" name="members['name']">
<input type="text" name="members['pwd']">
$members = $_GET['members']; ←methodが「GET」の場合。「POST」でも可能。
echo $members['id'];隠しフィールド
「type=”hidden”」で裏側で連携したい値を持たせる。
ただし、ディベロッパーツール等で直接ソース上の値を変えれば改ざん可能。
そのため、改ざんされては困る値についてはhiddenでは持たせず、
サーバー側に置いた値を使用するようにする。
//隠しフィールド
<input type="hidden" name="discount" value="10">リクエストの値を保持する方法
HTTPはリクエストの前後で状態を保持しない(ステートレス)プロトコルのため、
値を保持するには下記3つのいずれかの方法になる。
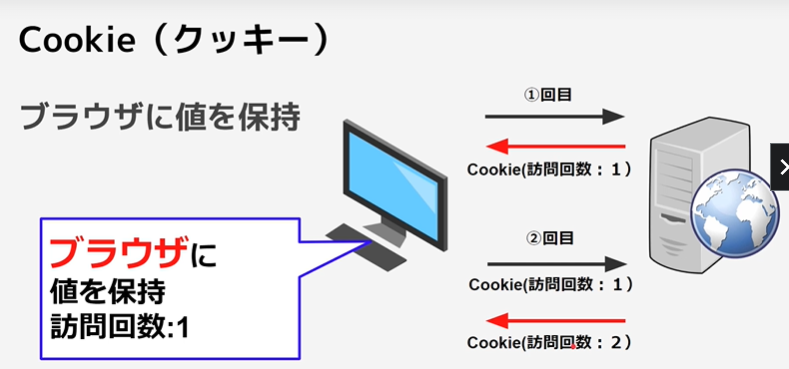
・ブラウザに保存
-①Cookie(クッキー)
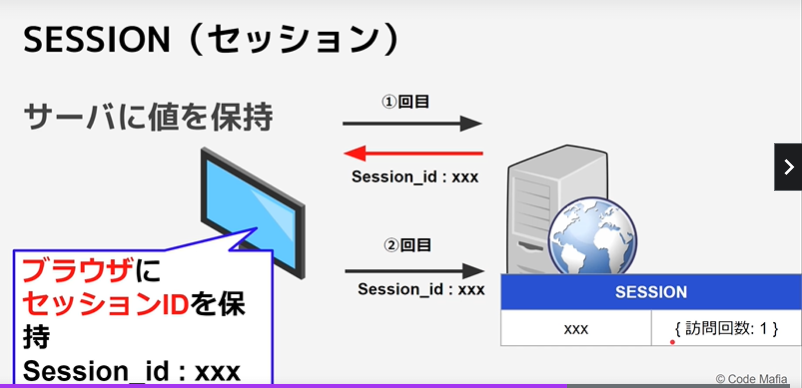
・サーバーに保存
-②Session(セッション)
-③DB(データベース)
リクエストを跨ぐ値の保持には基本的にSessionを利用する。
※Cookieはブラウザに保存する値なので、改ざんが可能。
CookieはセッションIDなど一意の値の保持に使う。
Cookie(クッキー)
httpヘッダーに値が保持される。
Session(セッション)
ブラウザからリクエストする事で、CookieにセッションIDが設定されたhttpヘッダーが返ってくる。
以降はhttpヘッダーにセッションIDが保持されるため、そのセッションIDをキーに付け合わせが可能。
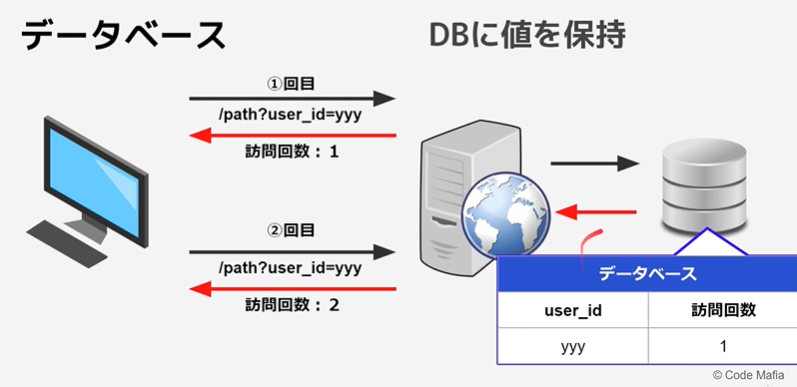
DB(データベース)
設定したキーを基にDBを参照。
PHPの基礎
不要な半角スペースの混入を防ぐために、<?php?>の閉じタグは削除しておく。
<?php
php文 php構文の外はhtmlタグとして認識されるため、
改行があると、半角スペースとして捉えられてしまう。
phpの閉じタグを省略しておけば、php文として処理されるため、改行があっても大丈夫。
シングルクォーテーションとダブルクォーテーションの違い
ダブルクォーテーション内だと、
・変数の展開ができる
・エスケープシーケンス(\nとか\t)が使用できる。
シングルクォーテーションだと上記ができない。
<?php
$name = 'Bob';
echo "hello, $name";→hello, Bob
<?php
$name = 'Bob';
echo "he{$name}llo,"
; →heBobllo,
※変数の前後に空白が無い場合は「{}」で囲む
<?php
$name = 'Bob';
echo "hello, $name\n\n\n";→hello, Bob
※ブラウザ上では3つの改行が入っている(<br>ではない)
代入について
<?php
$i = 1;
$j = 2;
//自己代入
//左辺と右辺に同じ変数があるものを自己代入という
$i = $i + $j;
→3
//自己代入演算子
$i += $j;
→3
$i .= $j;
→12
//インクリメント演算子
$i++;
→2データ型
「var_dump(変数)」でデータ型を出力する。
<?php
$i = 1;
var_dump($i);→int(1)
<?php
$b = true;
var_dump($b);→bool(true)
<?php
$str = 'hello';
var_dump($str);→str(5) “hello”
■注意点
・異なるデータ型の結合は自動的に片方のデータ型に変換される
$i + $b → 2
※trueは1としても扱われるから
・データ型の判定を行うときは、数字なのか文字なのか真偽なのか明確にしておく。
var_dump($i === 1) → true
var_dump($i === true) → ture
var_dump($i === ‘1’) → false
条件文
==と===の違い
== はデータ型の比較までは行わない
if (1 == '1'):→ 条件文は「true」になる
※左辺はint、右辺はstrだけどtrueになる
=== はデータ型の比較まで行う
if (1 === '1'):→ 条件文は「false」になる
※同じ「1」だが、左辺はint、右辺はstrだから
意図しない条件文がマッチしないように、可能な限り、「===」で行う方が良い。
falsyな値
下記の値は条件文で「FALSE」の扱いになる。
・””(空白)
・0(数値、文字列)
・NULL
・FALSE
issetとemptyの違い
isset は変数が定義されていて、null以外の値の時にtrueを返す。
empty は変数が定義されていない(つまりissetがfalse)、または値がfalsyな時にtrueを返す。
emptyをissetで表すこともできる。
if ( !isset($val) || $val == false ):
phpで「0」や「”(空白)」ではないかどうかを判定する場合は、emptyを使用する。
※issetでは「0」や「”(空白)」でも、空ではないと判断する。
if(!empty($val)) {
$valが0では無い時の実行文
}else{
$valが0の時の実行文
}//issetの挙動
$a = 0;
$b = 1;
$d = null
①
if(isset($a)) {
echo 'true';
}else{
echo 'false';
}
②
if(isset($c)) {
echo 'true';
}else{
echo 'false';
}
③
if(isset($d)) {
echo 'true';
}else{
echo 'false';
}→①変数が定義されていて、null以外だからtrue
※基本的に変数が定義されていればtrue
→②変数が定義されていないから、false
→③変数は定義されているが、値がnullなのでfalse
//emptyの挙動
$a = 0;
$b = 1;
$d = null
①
if(empty($a)) {
echo 'true';
}else{
echo 'false';
}
②
if(empty($c)) {
echo 'true';
}else{
echo 'false';
}
③
if(empty($d)) {
echo 'true';
}else{
echo 'false';
}→①は変数が定義されているが、falsyな値なのでtrue
→②は変数が定義されていないので、true
→③は変数が定義されているが、falsyな値なのでtrue
三項演算子
if文の記述を簡略化する事ができる。
$arry = [
'key' => 10,
]
//arryのkeyが定義されていて、null以外の値であれば
①
if(isset($arry['key'])) {
$arry['key'] *= 10;
}else{
$arry['key'] = 1;
}
②
$arry['key'] = isset($arry['key']) ? $arry['key'] *= 10 : 1;→①と②は同じ動作をする。
三項演算子
条件文 ? trueの時 : falseの時;
null合体演算子
値がnullかどうか判断する事ができる。
nullだった場合とそうでない場合で返す値を分岐させる。
$arry = [
'key' => 10,
]
//arryのkeyが定義されていて、null以外の値であれば
①
if(isset($arry['key'])) {
$outputval = $arry['key'];
}else{
$outputval = 1;
}
②
$outputval = isset($arry['key']) ? $arry['key'] : 1;
③
$outputval = $arry['key'] ?? 1;→①②③は同じ動きをする
null合体演算子
nullかどうか判定したい値(nullでは無い時の戻り値) ?? nullの時の戻り値
配列
配列の出力
$arry = ['taro','jiro','hanako']
①
for ($i = 0;i < count($arry); $i++) {
echo $arry[$i]
}
②
foreach( $arry as $val ) {
echo $val
}→①と②は同じ結果になる。
②の「foreach」を利用した方が条件文の記載が省略できるから楽。
$arry = ['taro','jiro','hanako']
foreach( $arry as $i => $val) {
echo $i.$val
}→foreachでインデクス番号を使いたい時は、
「$i => $val」とすると、インデックス番号を出力できる。
例:0taro 1jiro 2hanako
配列の操作
①array_shift($arry)
→配列の一番最初の値を削除する
②array_pop($arry)
→配列の一番最後の値を削除する
③array_splice($array,削除位置,何個消すか)
→配列の任意の位置の値を削除する
連想配列
連想配列はkeyとvalueがセットになっているもの
$arry = [
'nama' => 'Bob',
'age' => 12,
'sports' => ['baseball','swimming']
]
echo arry['name']; //Bob
echo arry['age']; //12
echo arry['sports'][1]; //swimmingforeach($arry as $key => $val){
echo "{$key}は{$val}"
}→連想配列もforeachを使用すれば、通常の配列の出力と同じ。
例:nameはBob
連想配列の値を削除する時は、
unset($arry[key])
を利用する。
※array_shift、array_pop、array_spliceも使用する事はできる。
正規表現
prag_match(“/検索するパターン/”,検索する文字列,マッチした文字列を格納する配列[省略可])
→マッチしたら「1」を返す、マッチしなかったら「0」を返す。
よく使う表現
- . 任意の一文字
- * 0回以上の繰り返し
- + 1回以上の繰り返し
- {n} n回の繰り返し
- [] 文字クラスの作成
- [abc] aまたはbまたはc
- [^abc] aまたはbまたはc以外
- [0-9] 0~9まで
- [a-z] a~zまで
- $ 終端一致
- ^ 先頭一致
- \w 半角英数字とアンダースコア
- \d 数値
- \ エスケープ
- () 文字列の抜き出し
$char = 'ZAabd12_sscc';
if(preg_match("/Aab/i", $char, $result)) {
echo '検索成功';
print_r($result);
} else {
echo '検索失敗';
}→検索パターンのオプションに「i」を付けると大文字小文字を区別しない。
自分が意図しないパターンで検索結果が一致している場合もあるので、
必ず第3引数の$resultの結果を確認し、一致内容を確認するようにする。
$char = '<h2>1ZAabd12_sscc</h2>';
if(preg_match("/<h2>(.{2,})<\/h2>/i", $char, $result)) {
echo '検索成功';
print_r($result);
} else {
echo '検索失敗';
}→「()」で囲む事で、囲んだ中身だけを抜き出し、第3引数の配列に追加する事が出来る
例:
Array(
[0] => <h2>1ZAabd12_sscc</h2>
[1] => 1ZAabd12_sscc
)
prag_match_all(“/検索するパターン/”,検索する文字列,マッチした文字列を格納する配列[省略可])
→マッチした回数を返す
$pregall = '好きなプログラミング言語はPHPです。今日もPHPを勉強しました。';
echo preg_match_all("/php/i",$pregall);→「2」が返ってくる。
関数
$price = 1000;
④
$price = with_tax($price);
function with_tax($base_price, $tax_rate = 0.1) {
$sum_price = $base_price + ($base_price * $tax_rate);
$sum_price = round($sum_price);
return $sum_price;
}
①
$price = with_tax($price);
②
$price = "with_tax"($price);
③
$fn = "with_tax";
$price = $fn($price);
echo $price;→引数に固定値代入しておくことで、引数の初期値を指定する事が可能。
→PHPは関数名を文字列にしても実行できる。
そのため、①②③はどれも正しく実行される
関数の重複
関数名が被るとエラーになる可能性があるので、重複していないか確認してから定義する
//fn1()が定義されていなければ
if(!function_exists('fn1')){
function fn1() {
echo 'test';
}
}複数名で開発したり、複数のモジュールを読み込んだ場合、関数名が被る可能性があるので、
必ず「function_exists」で確認してから定義する。
PHPDoc
PHPのコメントには決まった書式が存在する。
PHPでコメントを書く際は、「/** */」を用いる。
※コメントの文頭は必ず、「/**」で始める
また、決まった書式内のコメントでは、アノテーションが使用でき、
コード内容について、詳細な仕様を記載しておくことが出来るので、
複数人での開発時に役立つ。
参考:アノテーションの種類
https://zonuexe.github.io/phpDocumentor2-ja/references/phpdoc/index.html
例↓
/**
* 税率計算のための関数を記述するためのファイル
*
* @author CodeMafia ← 制作者の記入
* @since 1.0.0 ← バージョンの記入
*/
/**
* 税込み金額を取得する関数 ← 関数の内容
* ← 一行空ける
* @param int $base_price 価格 ← 引数(データ型と何の値か)
* @param float $tax_rate 税率 ← 引数(データ型と何の値か)
*
* @return int 税込み金額 ← 戻り値が有る場合(データ型と何の値か)
* @see https://example.com/ ← 参考URLがあれば
*/
function with_tax($base_price, $tax_rate = 0.1) {
$sum_price = $base_price + ($base_price * $tax_rate);
$sum_price = round($sum_price);
return $sum_price;
}
$price = with_tax(1000, 0.08);
echo $price;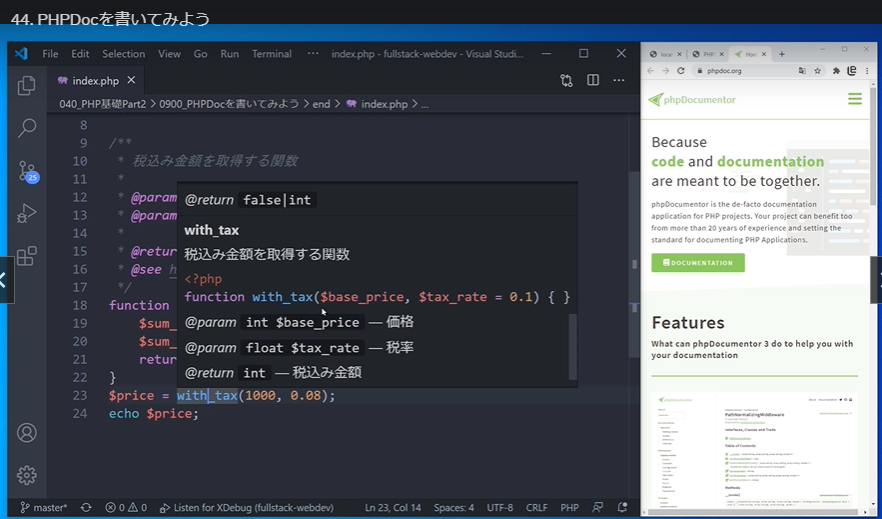
→PHPDocの書式に沿ってアノテーションを入れる事で、
関数にカーソルを合わせて、「Ctrl+Kケー Iアイ」を押すと使用方法が表示される。
スコープについて
スコープとは、変数が参照可能な範囲のこと
PHPでは、if文やfor文ではスコープされないので、変数の利用には注意
function fn() {
$b = 10;
if(true) {
$b = 2;
}
echo $b;
}→「2」と表示される。
※if文内ではスコープは変更されないため、
最初に定義した「$b = 10」は上書きされる。
グローバルスコープ
→関数に囲まれていないスコープ。
同じグローバルスコープ内であれば参照可能
<?php
$a = 1;
echo $a; ←表示可能ローカルスコープ
→関数で囲まれているスコープ。関数内でのみ参照可能。
ローカルスコープ内で
グローバルスコープの変数を参照する場合は、「global」の宣言が必要。
<?php
$a = 0;
function fn1() {
global $a; ←グローバルスコープの変数参照
$b = 2
echo $b; ←表示可能
}
echo $b; ←表示不可スーバーグローバール
→プログラム側で予め宣言されており、「global」宣言が必要無いグローバル変数。
※「$_SERVER」など
定数について
定数とは、一度定義したら上書きしない値のこと
定数の定義方法は下記の2つ
・const 変数名 = 値
・define(‘変数名’, ‘値’)
const
constはif文や関数の中では使えない
constは名前空間内に配置される
//税率を定義する
const TAX_RATE =0.1;※if文や関数内で使用できないので基本的にグローバルスコープ
define
defineはif文や関数の中でも使用できる
→「defined」関数を使用して定義されているかどうか確認が可能
defineはグローバルスコープに値が配置される
//税率を定義する
define('TAX_RATE', 0.1);
//TAX_RATEが定義されていなければ
if(!defined('TAX_RATE')) {
define('TAX_RATE', 0.1);
}※定数が重複しそうな場合は、definedで確認してから定義する。
基本的にはdefinedを挟んでの定義の方が良い。
ファイルの読み込みについて
ファイルの読み込み方法は2つあるが、
読み込むファイルが見つからなかった時の挙動が異なるので、
読み込むファイルの用途によって使い分ける。
PHPはファイル毎にスコープを持っている訳では無い。
読み込んだファイルはグローバルスコープに配置される。
※変数や関数が重複しないように気を付ける
・require(require_once)
・include
require(require_once)
読み込むファイルが見つからなかった場合、
致命的なエラーとなり、その時点で処理が停止され、以降の内容は実行されない。
そのため、絶対に読み込む必要があるファイル(関数など)では「require」を利用する。
//file1.phpの読み込み
require('file1.php');
require('file1.php');
require('file1.php');→「file1.php」内の内容は読み込んだ回数分実行される。
//file2.phpの読み込み
require_once('file2.php');
require_once('file2.php');
require_once('file2.php');→「file2.php」内の内容は1回しか実行されない。
※2回目以降の読み込みは無視される。
include
読み込むファイルが見つからなかった場合でも、
処理は止まらず、以降の処理も実行される。
そのため、最悪無くても動くファイル(htmlなど)では「include」を利用する。
//file1.phpの読み込み
include('file1.php');パスの書き方
マジック定数
__DIR__ → フォルダまでの絶対パスを出力
__FILE__ → ファイル名を含めた絶対パスを出力
// php
┗practice
┗file2.php
┗test
┗file1.php で実行
①
echo __DIR__; → php/practice/test
②
echo __FILE__; → php/practice/test/file1.php
③
echo __DIR__ . '../practice/file2.php'; → php/practice/file2.php
※相対パスも使用できるdirname
dirname(__FILE__) → フォルダまでの絶対パスを出力
※「__DIR__」と同じ振る舞いのように見えるが、dirnameに引数を指定すると階層をさかのぼれる。
// php
┗practice
┗file2.php
┗test
┗file1.php で実行
①
echo dirname(__FILE__); → php/practice/test
②
echo __DIR__ . '../practice/file2.php'; → php/practice/file2.php
③
echo dirname(__FILE__,2) . '/file2.php'; → php/practice/file2.php②と③は同じ動作になる。
パスの「\」と「/」について
基本的に「/」を使用する
※windowsやLinuxでは「\」と「/」どちらも使えるが、
UNIXでは「\」が使えない。
開発環境と本番環境のOSが異なった時、「\」だと最悪動かないので、
どの環境でも使用できる「/」を使う。
名前空間とは
プログラムの中で、同じ関数名やクラス名を使っても競合しないように「区分け」する仕組みのこと。
PHPでは同じ名前の関数やクラスを定義するとエラーになるが、別々の名前空間に所属させることで回避できる。
名前空間に登録できるのは、関数・定数・クラス、になる。
複数人で開発したり、ソースコードの規模が大きくなる場合は、他の誰かが付けた関数名やクラス名とたまたま被ってしまうことがあるかもしれません。
名前が被らないようにするには、誰も付けないような長い名前にする必要がありますが、それだとソースコードが読みづらくなってしまいます。
そこで、名前空間で区切る事で、関数名やクラス名を簡潔にし、可読性を保つ
名前空間は下記の形式で定義
namespace 空間名
※名前空間の宣言は必ず行頭で行う。名前空間の宣言より上に何かしらあるとエラーになる。
一つのファイル内で複数の名前空間を持つことも可能です。
// lib.php
<?php
namespace lib;
const str = 'test-lib';
function test() {
echo 'test-lib';
}
namespace lib2
//以降の記述は、「lib2」に属する// index.php
require_once('lib.php');
function test() {
echo 'test';
}
①
test();
②
\lib\test();test()という同名の関数だが、①②とも問題無く実行できる。
名前空間内の関数・定数・クラスを使用する場合は、
下記の記述
\(バックスラッシュ)名前空間名\(バックスラッシュ)関数・定数・クラス名
use
useを使用して名前空間の関数・定数・クラスを呼び出せる。
// index.php
require_once('lib.php');
use fucntion lib\test;
use const lib\str;
test();
echo str;use fucntion lib\(バックスラッシュ)関数名;
use const lib\(バックスラッシュ)定数名;
クラスについて
クラスとは、プロパティ(変数・定数)や、メソッド(関数)が一塊になった
プログラム処理をまとめたオブジェクトのこと。
//基本的なクラスの書き方
class クラス名
{
//プロパティの宣言
public $変数名 = 値;
//コンストラクタ(インスタンス化する際に一番最初に実行される)
public function __construct($name, $age)
{
$this->name = $name;
$this->age = $age;
}
//メソッドの宣言
public function メソッド名()
{
メソッド内処理...
}
}プロパティやメソッドの参照範囲は指定する事ができる。
・public → どこからでも参照可能
・private → 定義したクラス内でのみ参照可能
・protected → 定義したクラスと、そのクラスを継承したクラス内でのみ参照可能
「__construct」はnewでインスタンス化するとき(オブジェクトを生成するとき)に、
PHPによって自動的に一番最初に呼ばれる関数。
クラスを使用する時は、new を使用してインスタンス化して、オブジェクトにする。
//クラスのインスタンス化
$クラスオブジェクト = new クラス名();基本的な使い方
オブジェクト化したクラスから、内容を参照する時は「->(アロー演算子)」を使用する。
※静的メソッドの場合は「::(スコープ演算子)」
class Person
{
private $name;
public $age;
public function __construct($name, $age)
{
$this->name = $name;
$this->age = $age;
}
public function hello() {
echo 'hello, ' . $this->name;
}
}
$bob = new Person('Bob', 18);
$bob->hello();
// hello, Bob と出力されるクラス内の $this について
「$this」は newを使用して作成した自身のオブジェクトを指す。
※下記コードで言うと、「$bob」
class Person
{
private $name;
public $age;
public function __construct($name, $age)
{
$this->name = $name;
$this->age = $age;
}
public function hello() {
echo 'hello, ' . $this->name;
return $this;
}
public function bye() {
echo 'Good bye, ' . $this->name;
return $this;
}
}
$bob = new Person('Bob', 18);
$bob->hello()->bye();
// hello, Bob Good bey, Bob と出力される→「$this」は、自身のオブジェクトを指すので、「$this」をreturnした場合、
続けて他のメソッドを呼ぶことができる。
静的プロパティ・メソッド
クラス自身に登録しておけるプロパティやメソッド。
※プロパティ=変数、メソッド=関数
オブジェクト化させずに、クラスのままでも参照可能なプロパティやメソッド。
静的メソッドの中では「$this」は使用できない。
静的メソッドと一般メソッドの使い分けの基準は、「$this」を使うかどうか。
class Person
{
//静的プロパティの定義。記述方法は、「public static 変数名」
①
public static $hoge = 値;
②
public const hoge = 値;
function __construct($name, $age)
{
$this->name = $name;
$this->age = $age;
}
function hello() {
// 静的プロパティ・メソッドを参照する時は、「static::プロパティorメソッド」
③
echo static::hoge;
static::bye();
return $this;
}
//静的メソッドの定義。記述方法は、「static function 関数名()」
④
static function bye() {
echo 'bye';
}
}
$bob = new Person('Bob', 18);
$bob->hello();
//静的プロパティ・メソッドを参照する方法は2つ
⑤
//「クラス名::プロパティorメソッド」
echo Person::hoge;
⑥
//「オブジェクト::プロパティorメソッド」
echo $bob::hoge;静的プロパティの定義(①②どちらでも可能)
① public static $プロパティ
② public const プロパティ
③クラス内で静的プロパティ・メソッドを使用する場合
static::プロパティ・メソッド
④静的メソッドの定義
static function 関数名() {}
静的プロパティ・メソッドの参照(⑤⑥どちらでも可能)
⑤クラス名::プロパティ・メソッド
⑥オブジェクト名::プロパティ・メソッド
継承(extends)について
プロパティ・メソッドは継承元の内容を引き継ぐ。
また、継承先で継承元のプロパティ・メソッドを上書き(オーバーライド)できる。
//基本的な記述
class クラス名 extends 継承元クラス名{
処理…
}抽象化(abstract)について
抽象クラスとは他のクラスを継承して使用するためのクラス。
クラス内のメソッドで「abstract」を使用した場合、クラスも抽象化(abstract)する必要がある。
また、クラスを抽象化すると、そのクラスは直接インスタンスを生成できなくなる。
わざわざ「abstract」を使用する理由は、
継承先で指定したメソッドが存在していることを明示するため。
また継承先で宣言するメソッド名が開発者間でブレないようにするため。
//基本的な記述
abstract class 継承元クラス名{
public static $where = 'Earth';
abstract function hello(); ← 「abstract」を付けて関数を宣言。必ず継承先で定義する必要がある。
③
echo self::$where;
echo static::$where;
}
class クラス名 extends 継承元クラス名{
public static $where = '日本';
public function hello() {
処理…
}
④
echo self::$where;
echo static::$where;
}
①
$parent = new 継承元クラス名();
②
$child = new クラス名();①は「abstract」を使用しているため、エラーとなる。
②はオブジェクト化可能。
継承元と継承先で「self」と「static」の動作は異なる。
継承元で「static」を使用した場合は、継承先まで参照しにいく。
③は「Earth日本」
④は「日本日本」
Strictモード
declare(strict_types=1)
Strictモードにする事で、データ型の宣言を厳密にする事ができる。
指定したデータ型以外の場合、エラーになる。
データ型を厳密にすることで、値を厳密にし、予期しないエラーが起きないようにする。
<?php declare(strict_types=1);
/**
* データ型とStrictモード
*/
function add1 (int $val): int {
return $val + 1;
}
$result = add1(1);※プロパティデータ型を指定する場合、変数の前にデータ型を宣言する。
※戻り値のデータ型を指定する場合、関数名の後ろにデータ型を宣言する。
使用できるデータ型一覧
https://www.php.net/manual/ja/language.types.declarations.php#language.types.declarations.strict
Cookieの使い方
//基本的な使い方
setcookie('Cookieのキー', '設定する値', [
オプション
]);//例:訪問回数をCookieに保存
setcookie('VISIT_COUNT', 1, [
①
'expires' => time() + 60 * 60 * 24 * 30,
②
'path' => '/',
③
'secure' => true,
④
'httponly' => true
]);
⑤
$_COOKIE['VISIT_COUNT'];① expires
→Cookieの保持期間の設定
※time()で現在時刻を取得して、そこにどれくらいの期限を持たすのか追加する。
② path
→設定したCookieが有効な範囲の設定
※「/」であれば設定したドメイン配下全て。
何も設定しないと実行したファイルがあるパスでのみ有効になる。
③ secure
→通信をhttpsのみに制限する設定。
初期値はfalseだが、基本的にはtrueにする。
④ httponly
→Cookieの変更をhttpのみに制限する設定。
初期値はfalseだが、falseだとJavaScriptで変更可能になってしまう。
trueにする事でJavaScriptでの変更が不可になるため、
セキュリティ的に改ざんされて困る値の場合は、trueにする。
⑤ $_COOKIE[‘Cookieのキー’]
→Cookieの値を参照する場合のスーバーグローバル変数。
※Cookieの値は代入では上書きできない。
値を変更する時は、必ず「setcookie()」を利用する。
NG : $_COOKIE[‘VISIT_COUNT’] = 2;
OK : setcookie(‘VISIT_COUNT’,2,[…]);
SESSIONの使い方
Cookieと違いブラウザではなく、サーバー側に値が保持される。
//基本的は使い方
<?php
①
session_start();
②
$_SESSION['VISIT_COUNT'] = 1;① session_start();
→セッションを利用する場合は、行頭でセッションスタートを宣言する。
② $_SESSION[‘設定するキー’] = 1;
→セッションに値を設定する場合、スーパーグローバル変数を使って代入する。
SESSIONの値の保存場所
「phpinfo()」で表示される内容の、「upload_tmp_dir」に記載されているパスに作成される。
パスが設定されていなければ、下記のディレクトリが初期値。
・/bin/php/session
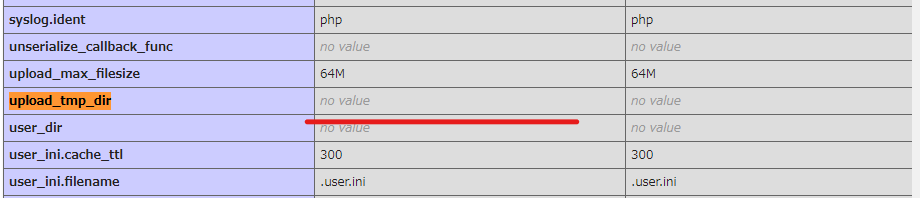
保存先のパスを変更したい時は、php.iniで下記の値を変える。
session.save_path = "/tmp/php/session"Apacheの基礎
Apacheとは?

モジュールの例:
mod_auth_basic → 基本認証
mod_dir → ディレクトリ事に設定
mod_rewrite → URLの書き換え
Apacheの設定

※ディレクティブとは → 命令という解釈??
コンテキストについて

Apache公式
https://httpd.apache.org/docs/2.4/mod/quickreference.html
.htaccessとは

.htaccessを利用するには、httpd.confで「AllowOverride All」を設定する必要がある
上記の設定を有効にした場合、Rootディレクトリ配下にある全てのフォルダに対して「.htaccess」が存在しているか確かめに行くため、パフォーマンスが低下する。
WEBとキャッシュ
WEBでキャッシュを制御する場合は、大別して下記の2パターンになる。
・ブラウザ側のキャッシュ
・サーバー側のキャッシュ

ブラウザのキャッシュ制御
ブラウザ側のキャッシュ制御は下記の2つ。
・「ETag」によるヘッダーが持つ値での判定
・「Last-Modified」による最終更新日時での判定

※INodeとは
→ファイルについている属性情報のこと。ファイル毎に一意の値が割り振られている。
ETagを使ったキャッシュ
ファイル更新の有無をETagの値を参照して判断する。
ファイルに更新があるとETagの値が変わるので、
リクエストヘッダーとレスポンスヘッダーでETagの値が同じであれば、
ファイルの更新は無かったと判断され、ブラウザのキャッシュが使用される。
※ブラウザのキャッシュが使われる場合のレスポンスコードは「304」
通信が行われた場合のレスポンスコードは「200」になる。
下記のファイルで使用可能
コンテキスト: サーバ設定ファイル, バーチャルホスト, ディレクトリ, .htaccess
//ETagの記述方法
# INode、更新日時、ファイルサイズを使用
FileETag All
FileETag INode MTime Size
# ETagなし
FileETag None
# 更新日時、ファイルサイズのみ使用
FileETag MTime SizeLast-Modifiedを使ったキャッシュ
キャッシュを使用するかどうかを「.htaccess内」で指定した期間で判断する。
キャッシュの期間については、
ETag同様にリクエストヘッダーとレスポンスヘッダーが持っている。
下記のファイルで使用可能
コンテキスト: .htaccess
// 記述例
<IfModule mod_expires.c>
ExpiresActive On
← 「Last-Modified」を利用する場合は、設定をONにする。
<FilesMatch "\.(png|jpe?g|gif|css|js|html)$"> ←どのファイルがどれだけキャッシュを持つか指定する。
ExpiresDefault "access plus 2 week"
</FilesMatch>
</IfModule>HTTP/1とKeepAlive
TCP接続をした際、サーバーのパフォーマンスを向上させる設定。
リクエスト毎に接続を確立するとサーバーに負荷がかかるため、
一度確立した接続を継続して使う事で、サーバーへの負荷を減らそうという仕組み。
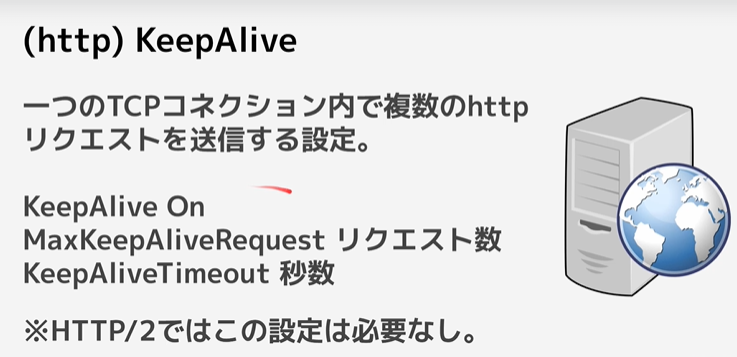
下記のファイルで使用可能
コンテキスト: サーバ設定ファイル, バーチャルホスト
//記述方法
KeepAlive On
MaxKeepAliveRequests 100 ←1ページ開く際に読み込むファイル数の総計に少し余裕を持たせた数
KeepAliveTimeout 1 ←長すぎるとサーバーでのプロセスが滞るので大体1秒くらい
→基本的にApacheであればOnになっている機能なので、設定値のみ調整する。
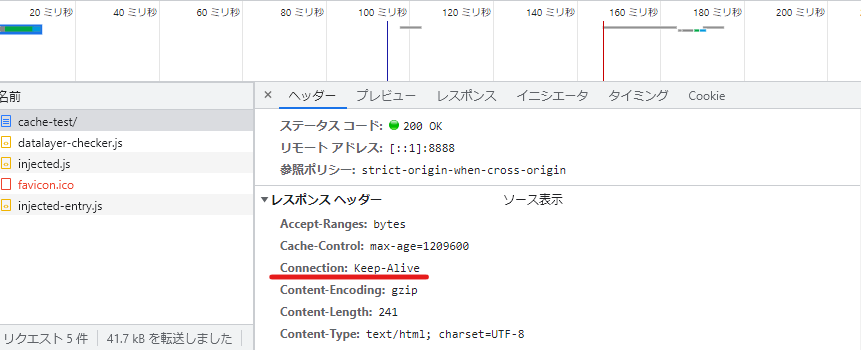
※KeepAliveが有効になっているかは、ネットワークからレスポンスヘッダーの設定をみれば分かる。
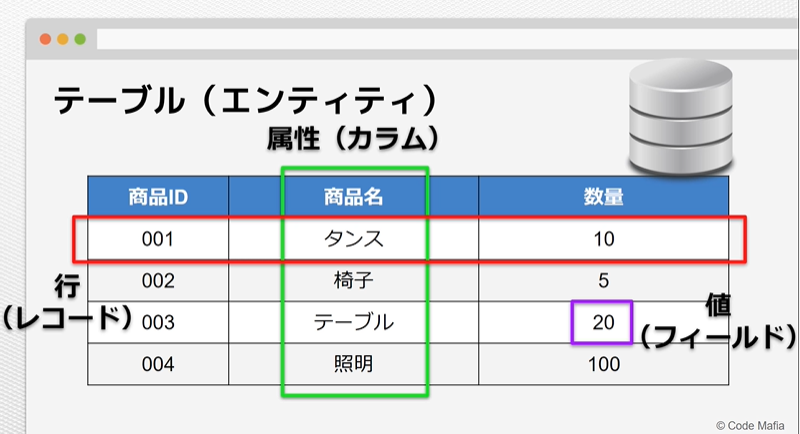
データベースの基礎
・テーブル(エンティティ)
・レコード(行)
・カラム(属性)
・フィールド(値)
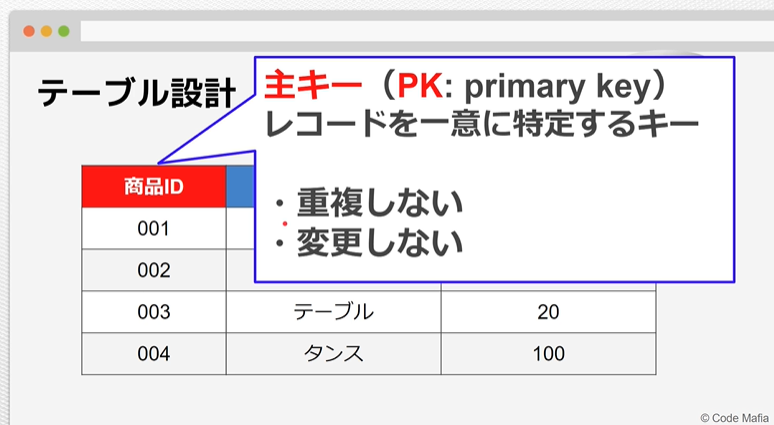
テーブルと主キー
主キー(primary key)とはレコードを特定するための一意の値のこと。
主キーが重複するとレコードの特定が困難になり、仕組みが破綻する可能性が出てくるため、
必ず後から変わる事のない一意の値を設定するようにする。
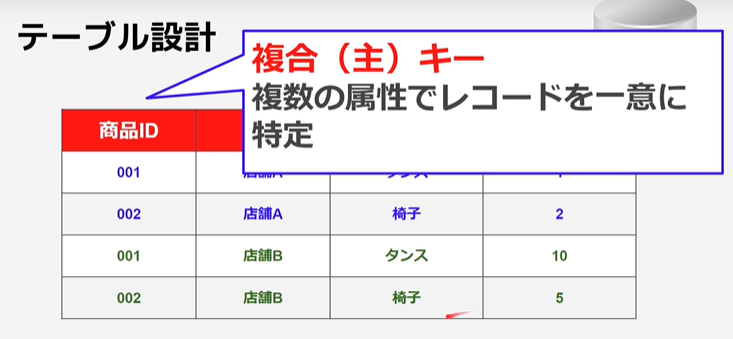
複合(主)キー
複数の属性でレコードを一意に特定させる。
例;
複数店舗でタンスという同一商品の在庫を管理する場合。
タンスはどの店舗でも同じ商品なので商品IDは統一したい。
しかし、それだと各店舗で同一の商品IDを持つことになるので、
店舗用のIDを掛け合わせる事で、レコードを特定させる。
外部キー
他のテーブルと結合するために使用するキー
全てのデータを一つのテーブルで管理するのではなく、
複数のテーブルを組み合わせる事で効率的な管理を行う。

テーブルの正規化
テーブルを定義する時の汎用的な考え方。
第1正規化~第5正規化まであるが、大体のケースは第3正規化くらいまでで十分。
非正規形
店舗情報が複数行にまたがってしまっているので、1行ごとに分ける必要がる。

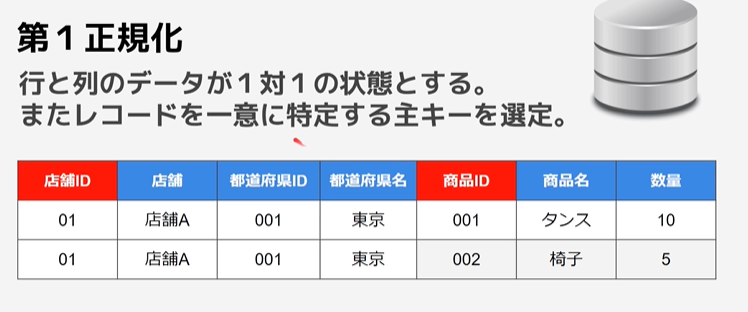
第1正規化
行と列のデータが1対1の状態になるようにする。
また属性に対してキーを振り、主キーになりそうな値を選定する。
第2正規化
主キーの一部に従属している属性(部分関数従属)を別テーブルに分ける。
※従属とは、
何かが決まれば特定されるような関係
例えば、「店舗ID」が決まれば、「店舗名と都道府県」は決まる。
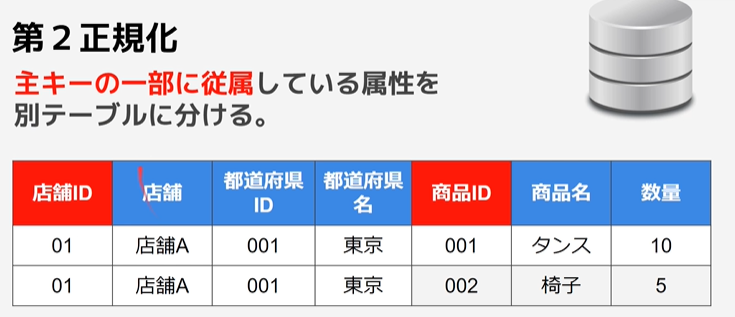
部分関数従属
主キー以外の属性によって特定される属性。
※上記のテーブルであれば、
・店舗ID→店舗名・都道府県
・商品ID→商品名
完全関数従属
主キーによって一意に特定される属性
※上記のテーブルであれば、
・店舗ID&商品ID→数量
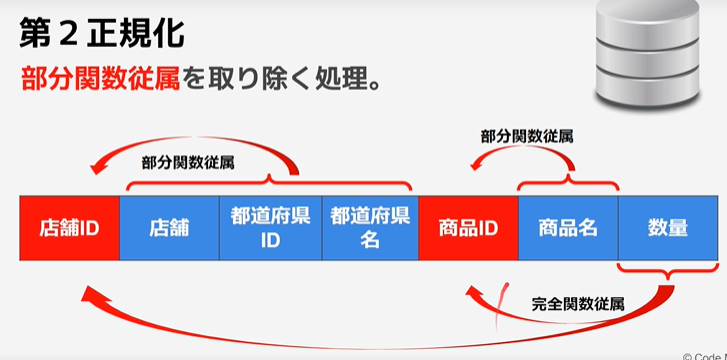
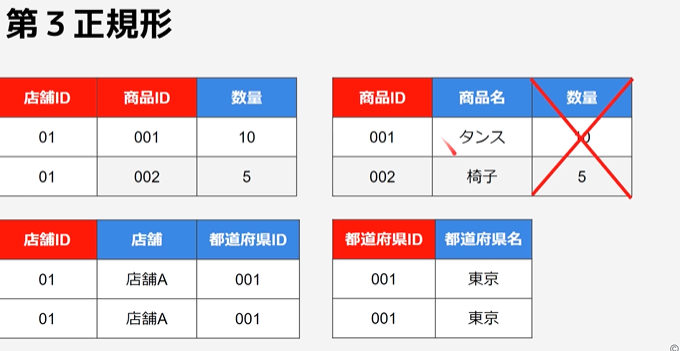
第3正規化
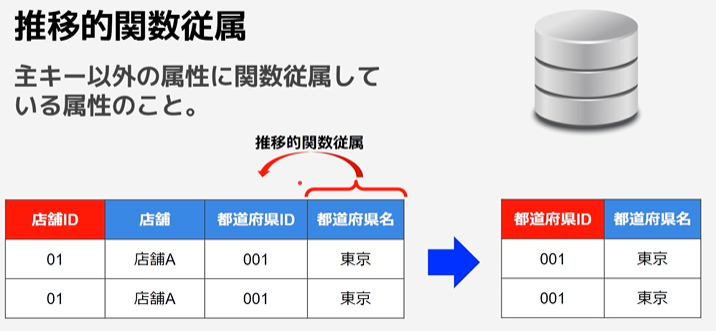
主キー以外の属性に従属している属性(推移的関数従属)を別テーブルに分ける。
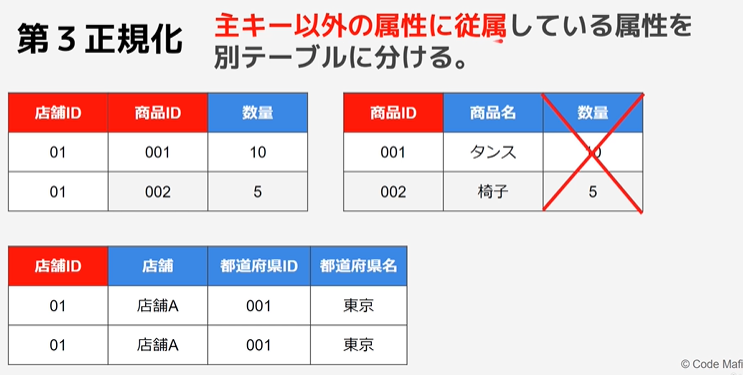
推移的関数従属
主キー以外の属性に関数従属している属性のこと。
※上記のテーブルであれば、「都道府県名」
第3正規化まで完了した状態のテーブル構成
ER図
テーブル(エンティティ)の関係を可視化するための記法の事。
※テーブルの正規化で分けたテーブルに対して関係性を記載する。
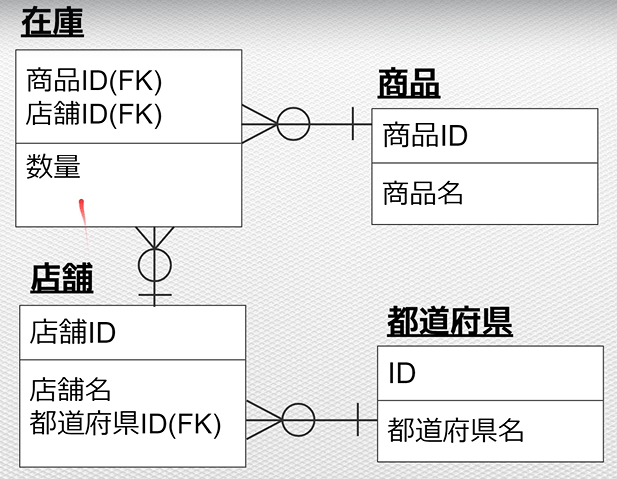
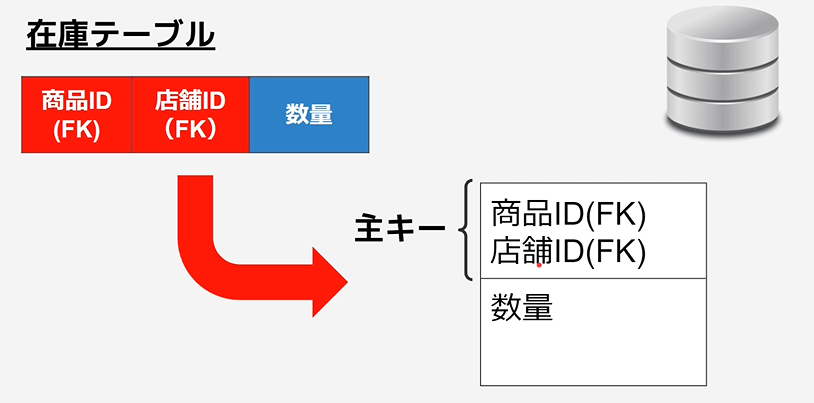
テーブル(エンティティ)の記載方法
主キーとそれ以外で分ける。
分ける際は、「水平線」で区切る。
例:在庫テーブルの場合
IE記法
ER図においてテーブルの関係性を表す代表的な記法
※他にも「IDEF1X記法」などがある。
テーブル同士のレコード数は、カーディナリティと呼ぶ。

例:「在庫テーブル」と「商品テーブル」の関係性
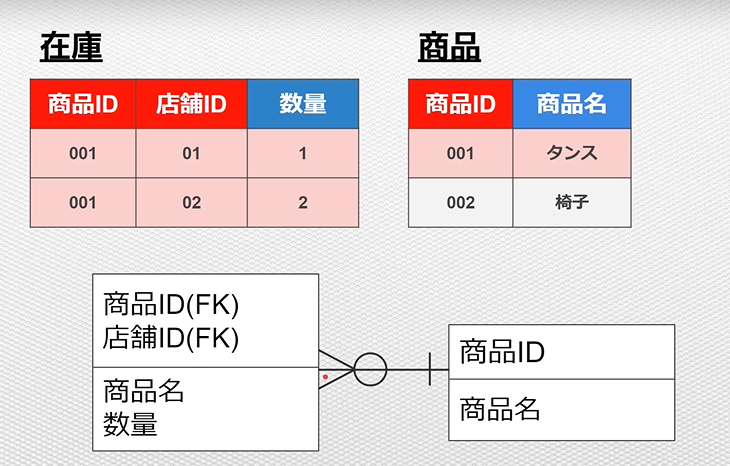
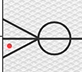
多(鳥の足)と○の組み合わせは「0以上」という意味になる。

「(FK)」は外部キーのこと。
DB
DBを作成する時は、可能な限り入ってくる値を決めておくようにする。
データ型や文字列の長さを予め決めておくことにより、
意図していない値が入ってくる事を防ぎ、動作やエラーに関して考慮すべき内容が減る。
SQL
DBを操作するための言語。
DBに対する命令の事をステートメントと言う。
※「SQLステートメント」と「クエリ」は同じ意味でどちらもSQLに対する命令のこと。
SQLの種類
主な種類は下記の2つ
・データ定義言語 – DDL(Data Definition Language)
DBオブジェクトの定義に使用
例:テーブル(table)
インデックス(index)
ファンクション(function)
トリガー(trigger)
…など
・データ操作言語 – DML(Data Manipulation Language)
テーブルデータの操作に使用
例:データの取得、更新、削除、挿入…など
SQLの記法

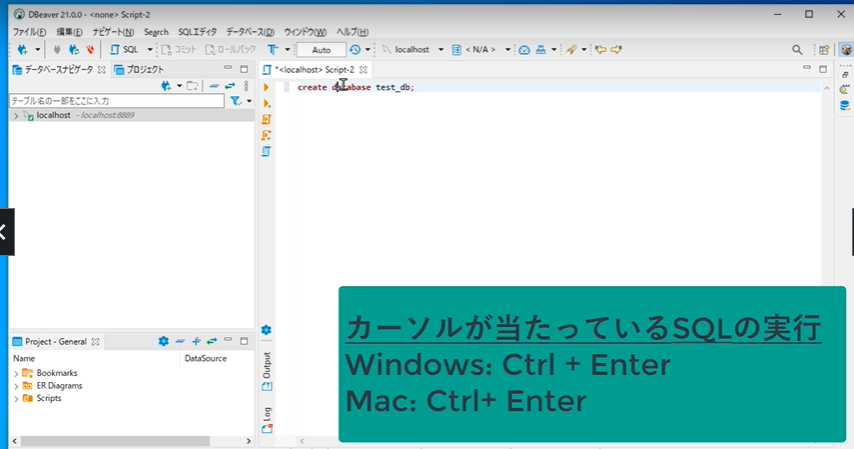
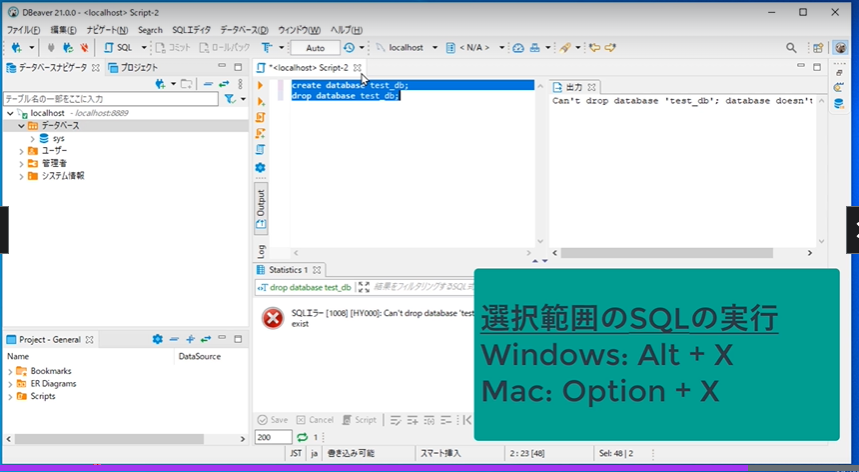
SQLクライアントの操作方法
SQLの基本的なデータ型
INT: 整数値
FLOAT: 浮動小数点
※「INT」「FLOAT」ともに、正の値に限定する場合は unsigned を使用。
unsignedを使用すると指定した桁数での0詰めが行われる。
例:int(6)に「1」をいれると、「000001」になる。
DATETIME: 日時
TIMESTAMP: 日時
CHAR: 固定長文字列
VARCHAR: 可変長文字列
BLOB: バイナリデータ(画像や音声、動画など)
テーブルの作成
複数行ある場合は、「,」で区切る。
最後の行には「,」付けない。
create table DB名.テーブル名 (
カラム名 データ型 default デフォルト値 制約 comment 'コメント',
カラム名 データ型 default デフォルト値 制約 comment 'コメント'
...,
表制約
)制約の作成
DBを作成する時は、可能な限り入ってくる値を決めておくようにする。
データ型や文字列の長さを予め決めておくことにより、
意図していない値が入ってくる事を防ぎ、動作やエラーに関して考慮すべき内容が減る。
- 表制約
表(テーブル)に対して行う制約
例)複合主キー、外部キー制約など - 列制約
列に対して行う制約
例)NOT NULL 制約など
制約
UNIQUE: 一意制約
NOT NULL: NOT NULL制約
PRIMARY KEY: 主キー制約
FOREIGN KEY: 外部キー制約
CHECK: チェック制約 (MySQL8.0)
例:テーブルに入る値を、「データ型」「文字数」「値」で制約している。
create table test_table(
id int(6) default 0 not null comment 'ID',
val varchar(20) default 'hello' unique comment '値'
);
primary key(プライマリーキー)の作成
primary keyは基本的に、「一意の値で後から変更しない」値を指す。
primary keyには、下記の2つがある。
・単一主キー
・複合主キー
単一主キー
create table test_table(
key1 int primary key
);
複合主キー
create table test_table(
key1 int,
key2 int,
primary key(key1, key2)
);
auto_increment(オートインクリメント)の注意点
オートインクリメントは、自動で連番を振ってくれる機能。
そのため、基本的にデータ型は「int」となる。
主キーを設定する必要があるが、特に決められた値を設定する必要が無い場合などによく使う。
ただし、利用の際は下記3つの制限がある事を認識しておく。
- オートインクリメントを利用する属性は、indexを持っている必要がある
- 1つのtableで1回しか使用できない
- default値を持たせる事ができない
- deleteで削除しても番号は戻らないので初期化する必要がある。
- オートインクリメントを利用する属性は、indexを持っている必要がある
index(インデックス)とは、検索を高速化させるための仕組みだと思っておけばOK。
「primary key」や「unique」を設定すると自動でindexを持つ。
上記の設定以外でも、indexを明示的に設定することも可能。
create table DB名.テーブル名(
key1 int auto_increment,
index(key1) ←明示的なindexの設定
);- deleteで削除しても番号は戻らないので初期化する必要がある。
-- auto_incrementの初期化
alter table テーブル名 auto_increment = 1;
テーブル定義の確認
「desc」だけでは、commentで持たせた内容は表示されない。
「show full columns from ~~」であれば、commentで持たせた内容も表示される。
「show create table ~~」は、定義したテーブルの全設定が表示されるので、慣れてきたらこのクエリで確認した方が早くなるかも。
desc DB名.テーブル名;show full columns from DB名.テーブル名;show create table DB名.テーブル名;アクティブなDBの指定
アクティブなDBを指定しておけば、クエリ内のDB名の指定は省略できる。
例:create table テーブル名 =(イコール) create table DB名.テーブル名
use DB名;アクティブなDBの確認
select database();テーブル定義の変更
create tableで作成したテーブルのカラムに変更を加える。
alter table テーブル名
実行文1,
実行文2;カラムの追加
追加する属性の記述方法や制約は、create tableと同じ。
「after」や「first」を使用して、任意のkeyの後に新規でカラムを追加する事もできる。
alter table テーブル名
add colmun key2 varchar(20) not null after key1,
add colmun key2 varchar(20) not null;カラムの情報の変更
例:データ型をintに変更する場合
alter table テーブル名
modify colmun key2 int;カラムの削除
alter table テーブル名
drop colmun key2;外部キー
子テーブルに外部キー(fk)制約を定義する。
※外部キー(fk)は、子テーブルから親テーブルに貼るイメージ。
https://dev.mysql.com/doc/refman/8.0/ja/create-table-foreign-keys.html
alter table テーブル名
add constraint ①制約名(※削除する際に使用)
foreign key (対象のキー名)
references 親テーブル名(テーブルキー名)
on update cascade
on delete restrict; -- 省略可外部キーを設定する時の注意点
- 型情報は合わせる
※データ型がint(6)なら、親も子もint(6)になってないといけない - インデックスの自動付与
(すでに有効なキーが存在する場合には作成しない。
例:複合主キーの一番最初はインデックスが作成されない。)
on delete: レコードが削除された際のアクション
on update: レコードが更新された際のアクション
┗ cascade:
親テーブルのレコードを更新または削除した場合、子テーブル内の一致するレコードの値も自動的に更新または、削除します。
┗ restrict:
親テーブルに対する削除または更新操作を拒否します。
ON DELETE または ON UPDATE 句を省略することと同義。
例:prefテーブルの内容をshopsテーブルで参照する
alter table shops //外部キーの制約を定義する子テーブルの選択
add constraint fk_pref_id //「制約名」は「fk_」+「キー」のルールで付ける
foreign key(pref_id) //外部キーの制約を付けるキーの選択
references prefs (id) //外部キーを貼る親テーブルのキーの選択
on update cascade; //アップデートがあった時の動作の指定。※未指定だと「restrict」になる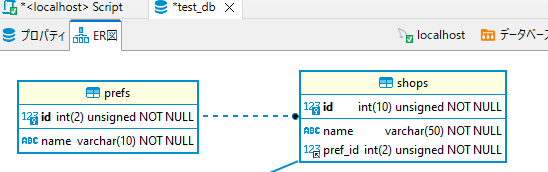
実践的なテーブル定義
テーブルは下記の2種類に分ける事ができる。
- 参照値を保持する用の「マスターテーブル」
- アプリからデータを頻繁に挿入、更新するような「トランザクションテーブル」
マスターテーブル
参照値を保持する用のテーブル。
アプリからは基本的に値を挿入、変更しない。
例:商品一覧、店舗一覧など
テーブル作成時は、先頭にmstとつけることが多い。
例:mst_products
トランザクションテーブル
アプリからデータを頻繁に挿入、更新するようなテーブル。
エントリーテーブルとも呼ぶ。
例:オーダー情報、顧客情報、請求情報など
テーブル作成時は、先頭にent, txn, trnとつけることが多い。
例:txn_stokcs
また、レコードの管理の為、下記のような属性を持たせておくとよい。
■ 論理削除フラグの導入(delete_flg)
レコードの有効性を識別するためのフラグ
例:delete_flg = 1の場合には無効レコードとして扱う。
■ 更新日、更新者の導入(updated_at, updated_by)
レコードがいつ、誰によって変更されたのかの証跡を保持するための属性
create table mst_products (
id int(10) unsigned auto_increment primary key,
name varchar(20) not null,
delete_flg int(1) not null default 0,
updated_at timestamp default current_timestamp on update current_timestamp,
updated_by varchar(20) not null
);
create table txn_stocks (
product_id int unsigned,
shop_id int unsigned,
amount int unsigned not null,
delete_flg int(1) not null default 0,
updated_at timestamp default current_timestamp on update current_timestamp,
updated_by varchar(20) not null,
primary key (product_id, shop_id)
);
レコードの追加
insert into テーブル名(属性1, 属性2) values (値1, 値2);
※複数追加する場合は、値を「,」で区切る
外部キー制約を付けている場合、
親テーブルに存在しない値を入れようとするとエラーになるため、
必ず「親テーブル→子テーブル」の順番で値を入れるようにする。
insert into test_db.mst_prefs(name, updated_by) values ('北海道', 'codemafia');
insert into
test_db.mst_prefs(name, updated_by)
values
('山形', 'codemafia'),
('青森', 'codemafia');レコードの取得
select ①取得したい属性 [as label] from テーブル名 [as alias]
※[]は省略可
「①取得したい属性」は下記の指定が可能
* : すべての属性を取得
count(*) or count(1) : レコード件数を取得
as : 列ラベルの変更(asは省略可能)
distinct : 重複レコードを省く
-- name: name属性を取得
select name from test_db.mst_prefs;
-- *: すべての属性を取得
select * from test_db.mst_prefs;
-- count(*): レコード件数を取得
select count(*) from test_db.mst_prefs;
select count(1) from test_db.mst_prefs;
-- as: 列ラベルの変更(asは省略可能)
select id as "ID", name as "都道府県名" from test_db.mst_prefs;
-- distinct: 重複レコードを省く
select distinct name "都道府県名" from test_db.mst_prefs;
-- 重複行を省いた件数
select count(distinct name) from test_db.mst_prefs as mp 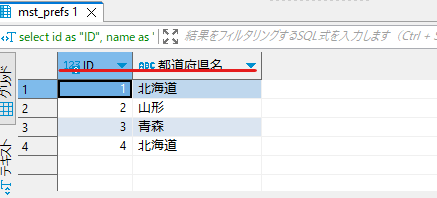
レコードの削除
delete from レコードを削除するテーブル [条件(where)];
外部キー制約を付けている場合、
子テーブルから参照されているレコードが存在するとエラーになる(deleteの動作がrestlictの場合)
delete from test_db.mst_prefs;条件句(where)
-- = : 一致
select * from test_db.txn_stocks
where 属性1 = 1;
-- <>, != : 非一致
select * from test_db.txn_stocks
where 属性1 != 1;
-- >, >=, <, <= : 数値の比較
select * from test_db.txn_stocks
where 属性1 >= 60;
-- A and B : A かつ B
select * from test_db.txn_stocks
where 属性1 = 1 and 属性2 = 1;
-- A or B : A または B(属性と値でのor検索)
select * from test_db.txn_stocks
where 属性1 = 1 or 属性2 = 1;
-- () : 条件をくくる
select * from test_db.txn_stocks
where (属性1 = 1 and 属性2 = 1)
or (属性1 = 2 and 属性2 = 2);
-- like : %で部分一致検索(複数文字)
-- _とした場合には一文字に一致
select * from test_db.mst_shops
where 属性1 like '店%'; //←"店舗"や"店舗A"などがヒット
where 属性1 like '店_'; //←"店舗"がヒット
-- in : いずれかの値に一致(値のor検索)
select * from test_db.mst_shops
where 属性1 in ('店舗A', '店舗B');
-- not in : いずれの値にも一致しない
select * from test_db.mst_shops
where 属性1 not in ('店舗A', '店舗B');
-- between A and B: A から B の値
select * from test_db.txn_stocks
where 属性1 between 60 and 100;
-- is not null : null以外に一致
select * from test_db.txn_stocks
where 属性1 is not null;
-- is null : nullに一致
select * from test_db.txn_stocks
where 属性1 is null;ソート順
select * from テーブル名 order by 属性 desc;
デフォルトは「asc(昇順)」
降順を指定する場合は、「desc(降順)」
複数属性によるソートは「,」で区切る
-- 単一キーによるソート
select * from テーブル名
order by 属性1 desc;
-- 複数キーによるソート
select * from テーブル名
order by 属性2 desc, 属性3 asc;
-- 条件付き
select * from テーブル名
where 条件
order by 属性2 desc, 属性3 asc;
取得レコード数の指定
「limit」と「offest」を使用する
※「offest」は「0」スタート
「offest」を省略する場合は、「offest」の値を前にして「,」で区切る
select * from テーブル名 limit 2; //←上から2レコード分取得
select * from txn_stocks limit 2 offset 1; //←上から2レコード目から、2レコード分取得
select * from txn_stocks limit 1, 2; //←上から2レコード目から、2レコード分取得レコードの更新
update テーブル名 set 属性1 = 値1, … where 条件
※updateを行う場合はまず、select文で対象のレコードの値を確認してから行う。
いきなりupdateを行うと、意図していない範囲まで影響する可能性があるので気を付ける。
-- ①更新前の確認
select * from test_db.txn_stocks
where shop_id = 1 and product_id = 1;
-- ②在庫数を特定の値に変更(50)
update test_db.txn_stocks set amount = 50
where shop_id = 1 and product_id = 1;必ず①のselect文で範囲を確認。その後、update文を書いて、①のwhere条件をそのまま利用する。
-- 在庫数から 10 引く
update test_db.txn_stocks set amount = amount - 10
where shop_id = 1 and product_id = 1;値の変更は現在値の参照でも可能。
テーブルの結合
・内部結合(inner join)
・左外部結合(left join)
・右外部結合(right join)
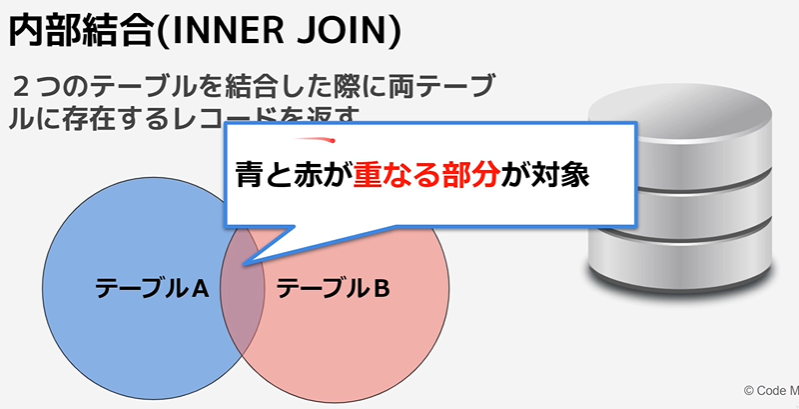
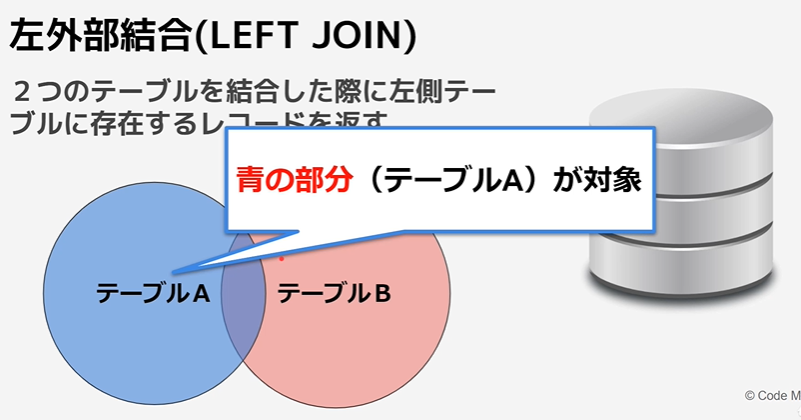
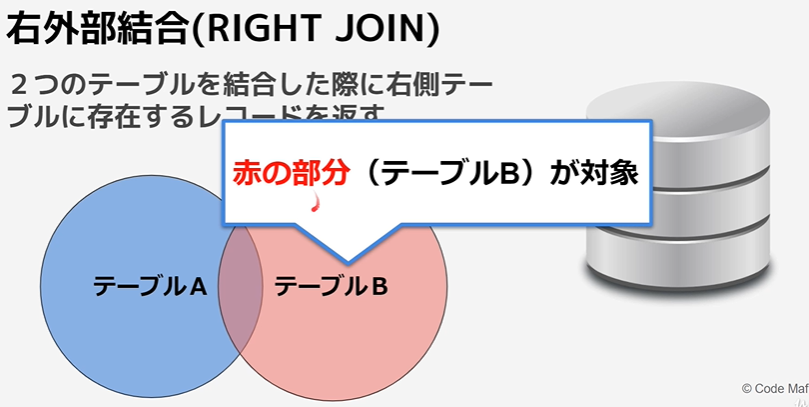
内部結合
select * from テーブル1
inner join テーブル2
on テーブル1.値が一致する属性 = テーブル2.値が一致する属性;
※*だとデータが多くなってしまうので、通常は属性を絞る。
①
select * from mst_shops ms //←この「ms」は指定したテーブルのエイリアス。短縮された文字のこと
inner join mst_prefs mp //←「mp」は上記と同じ。指定したテーブルのエイリアス。
on ms.pref_id = mp.id;
②
select ms.name, mp.* from mst_shops ms //←左と右テーブルの範囲を指定する
inner join mst_prefs mp
on ms.pref_id = mp.id;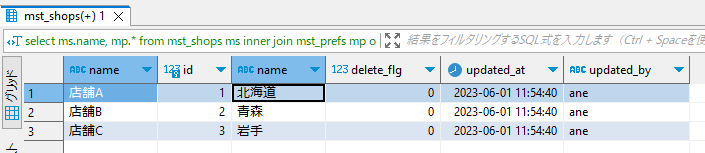
①のようにselect文で*を使用するとデータが多いため、基本的にselect文の範囲は絞るようにする。
③
select ms.name as "店舗名", mp.name as "都道府県名" from mst_shops ms
inner join mst_prefs mp
on ms.pref_id = mp.id;
④
select ms.name as "店舗名", mp.name as "都道府県名" from mst_shops ms
inner join mst_prefs mp
on ms.pref_id = mp.id
where pref_id = 1;
③
select ms.name as "店舗名", mp.name as "都道府県名" from mst_shops ms
inner join mst_prefs mp
on ms.pref_id = mp.id;
⑤
select ms.name as "店舗名", mp.name as "都道府県名" from mst_shops ms , mst_prefs mp
where ms.pref_id = mp.id;外部結合
select * from 左テーブル
left join 右テーブル
on 左テーブル.値が一致する属性 = 右テーブル.値が一致する属性;
※「左外部結合」と「右外部結合」が存在するが、特別な理由がなければ「左外部結合」で良い。
select mp.name as "都道府県名", ms.name as "店舗名" from mst_prefs mp
left join mst_shops ms
on mp.id = ms.pref_id;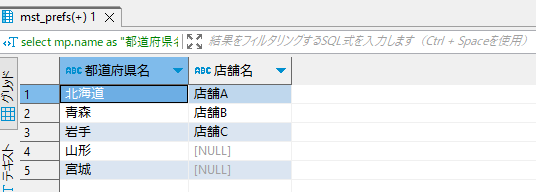
トランザクションについて
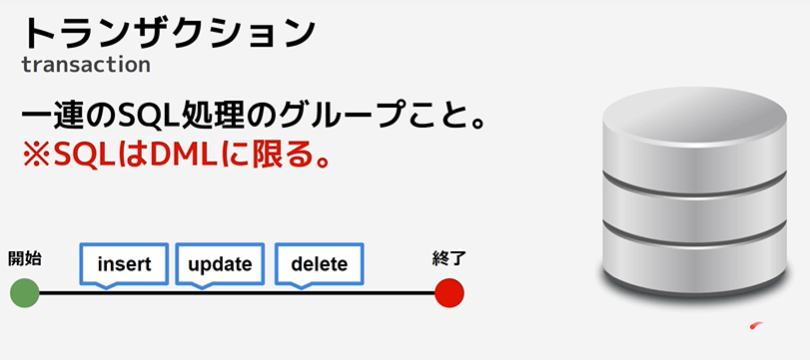
トランザクションの開始
start transaction
上記の宣言を使用すると、「commit」を実行するまで、実行内容はDBに反映されない。
上記の宣言を使用すると、「rollback」を実行することで、transactionが開始される前の状態まで戻れる。
※transactionはセッションごとに独立しており、「commit」が実行されるまで他のセッションからは実行内容を見る事ができない。同一のセッションであれば、「commit」前でも実行後の結果は確認可能。
→「ACID特製」と言う
※商用のDBを編集する際は、必ずtransactionを張ってから行う。transactionがあれば万が一、誤ったクエリを流してもrollbackで戻る事ができる。
※rollbackしても、auto_incrementの値は元に戻らない。transaction内でカウントアップが起きるような処理が行われた場合、rollbackで処理を中断してもカウントアップされたままになる。
start transaction;
~実行内容~
-- 成功
commit;
-- 失敗
rollback;PHPとDB
DBへの接続方法
new PDO(データベース情報, データベースユーザー, データベースパスワード);
定型の記述補法
$user = 'test_user';//データーベースユーザー
$pwd = 'pwd';//データベースパスワード
$host = 'localhost';//データベースのホスト名
$dbName = 'test_phpdb';//データベース名
$dsn = "mysql:host={$host};port=8889;dbname={$dbName};";
try {
$conn = new PDO($dsn, $user, $pwd);
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);//PDOオブジェクトのエラーを検知
$conn->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC);//取得するデータを連想配列形式で取得
echo "データベースへの接続に成功しました";
~実行内容~
} catch(Error $e) {
//通常はページ上にエラー内容までは記載しない
echo "データベースへの接続に失敗しました: " . $e->getMessage();
}
$conn = null; //都度、DBとのコネクションは解除する※PDOでは不要だが定型として記載DBから情報の出力
$sql = 'select * from mst_shops';//データを取得するテーブルの指定
$pst = $conn->query($sql);//クエリのセット
$result = $pst->fetchAll(PDO::FETCH_ASSOC);//取得したデータを配列として格納※「PDO::FETCH_ASSOC」の指定で連想配列での取得になる。setAttributeで指定していたら都度は不要DBの情報更新
$result = $conn->exec('update mst_prefs set name = "福島" where id = 5');
echo '<pre>';
print_r($result);
echo '</pre>';上記の記述を行ったphpファイルでの「$result」の値は、初回は「1」と表示されるが、
2回目は「0」と表示される。
※2回目はid=5のnameが既に「福島」に書き換わっておりDBの更新が起きないため「0」となる。
例外処理
エラーが発生しそうな内容については例外処理で括るようにする。
例外処理の中でのエラーであれば、処理を分ける事が出来るが、
例外処理の外でのエラーに関してはエラーでページ自体が止まってしまう。
try {
echo '通常処理が最後まで実行されました。<br>';
} catch(①Error $e) {
echo '例外処理が実行されました。<br>';
echo $e->getMessage() . '<br>';//エラーの内容を表示
echo get_class($e) . '<br>';//エラーの型を表示
} ②finally {
echo '終了処理が実行されました。<br>';
}①エラーの型を宣言する事でキャッチするエラーの内容を細かく絞る事ができる。
https://www.php.net/manual/ja/language.errors.php7.php
上位階層のエラー種類を指定しておけば、下層のエラーは全てキャッチできるようになる。
例:catch(Throwable $e)としておけば、全てのエラーをキャッチする
②finallyの節は、必ず最後に実行される節となる
例外処理2
①function throwException() {
try {
new PDO('', '', '');
echo '通常処理が最後まで実行されました(function内)。<br>';
} catch(Error $e) {
//echo 'PDOException<br>';
echo '例外処理が実行されました(function内)。<br>';
echo $e->getMessage() . '<br>';
echo get_class($e) . '<br>';
}
}
②try {
throwException();
echo '通常処理が最後まで実行されました(上位層のtry)。<br>';
} catch(Throwable $e) {
echo '例外処理が実行されました(上位層のtry)。<br>';
echo $e->getMessage() . '<br>';
echo get_class($e) . '<br>';
} finally {
echo '終了処理が実行されました。<br>';
}
echo 'finallyの後です。';try{}の例外処理は。try{}で囲まれている上位層までさかのぼって実行される。
上記のコードであれば、
まず、「①throwException関数」内の例外処理のチェック入って、
その後、「②try」内の例外処理のチェックが入る。
上記の場合、「①throwException関数」で宣言しているcatchのエラー型では
PODエラーがマッチしないため、「②try」内のcatchでエラー内容が出力される。
通常、上位層のtryでは包括的なエラー型を宣言しておき、
下層で細かいエラーをキャッチできるようにしておく。
